




“Regular Expressions,” often abbreviated as “RegEx,” is a powerful technique used to identify specific patterns within given combinations of text or data. These patterns serve as effective filters, enabling you to precisely extract the desired information.
How to use Regex for web scraping
When it comes to web scraping, Regular Expressions are invaluable for defining search patterns to match and extract specific data from web content.
Hexofy also provides a feature for filtering data using regular expressions. This capability is particularly handy when dealing with fields containing multiple pieces of data or when you need to skip certain information.
Here are some pattern examples to illustrate how Regex works in web scraping with Hexofy:
YouTube: Retrieving the Number of Subscribers
To obtain the number of subscribers on a YouTube channel, follow these steps:
Step 1: Select the element
Begin by navigating to the YouTube page you wish to scrape. For this example, let’s consider the following YouTube video: https://www.youtube.com/watch?v=0pwYLCMccvU.
Once you are on the page, identify the HTML element that contains the information regarding the number of subscribers. This element typically includes the subscriber count.
Step 2: Enter the following pattern: .*(?=subscribers)
Once you click on the number of subscribers, you’ll be able to copy and paste the relevant regex pattern inside the Pattern field.
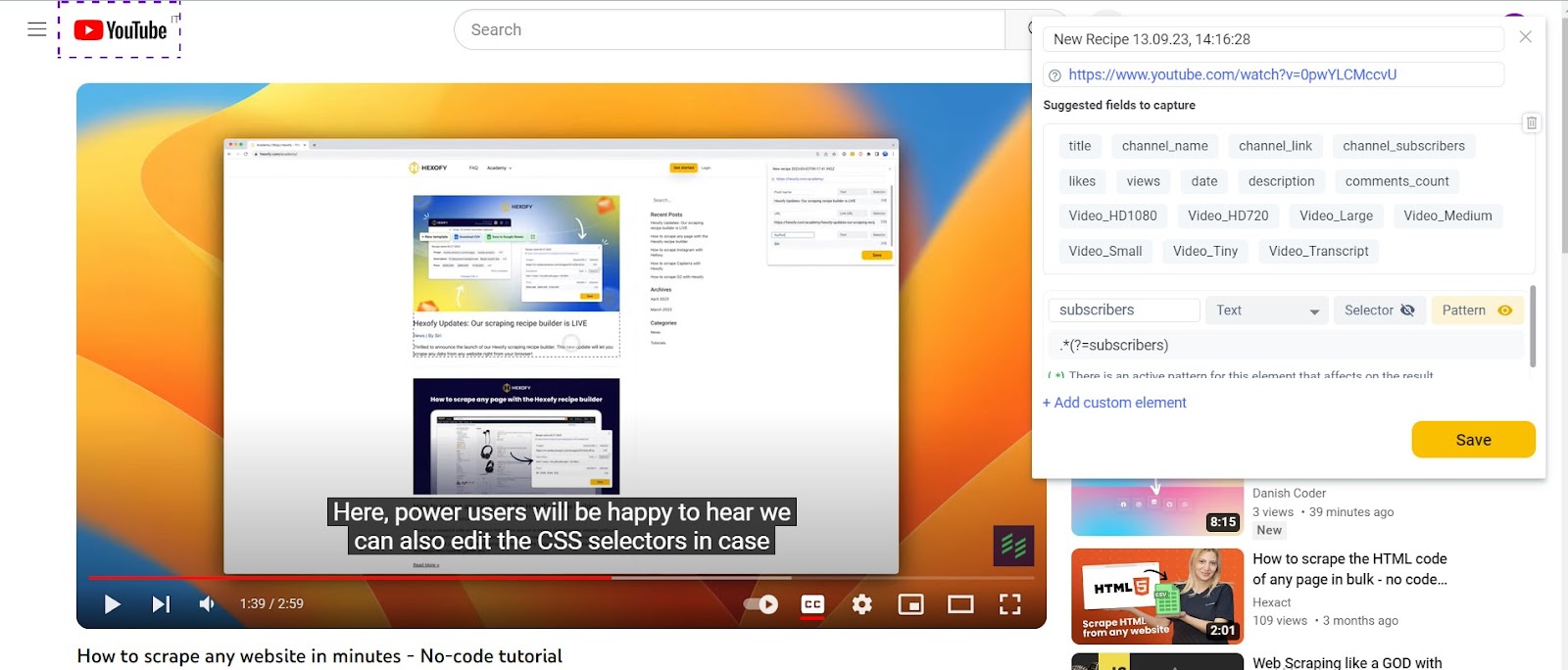
This regex pattern, .*?(?=subscribers), serves the purpose of locating and retrieving the text that precedes the term “subscribers” on a webpage.
Let’s delve into the pattern to gain a clearer understanding of why it is used:
The .* part corresponds to match any sequence of characters (the dot, “.”, matches any character, and the asterisk, “*”, signifies zero or more occurrences).
The (?=subscribers) portion is a lookahead assertion that verifies the presence of the word “subscribers” right after the matched characters.
In essence, this pattern captures all the characters leading up to the term “subscribers” but does not include the word “subscribers” itself.
Step 3: Save the element
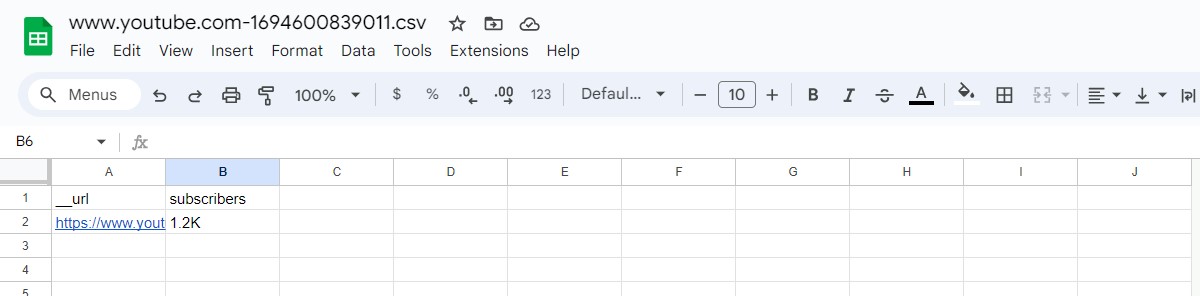
Once you’ve applied the regex pattern to the designated element, you’ll be able to retrieve the text that matches it, typically indicating the count of subscribers.
This extracted information can then be saved in a Google Spreadsheet and later used according to your requirements. By adhering to these steps, you can easily get the subscriber count from the specified YouTube page.
Twitter: Scrape post date and time in separate columns
The following patterns will help you scrape the Twitter post date and time separately and add the data in 2 different columns.
Scrape post date:
Step 1: Select the element
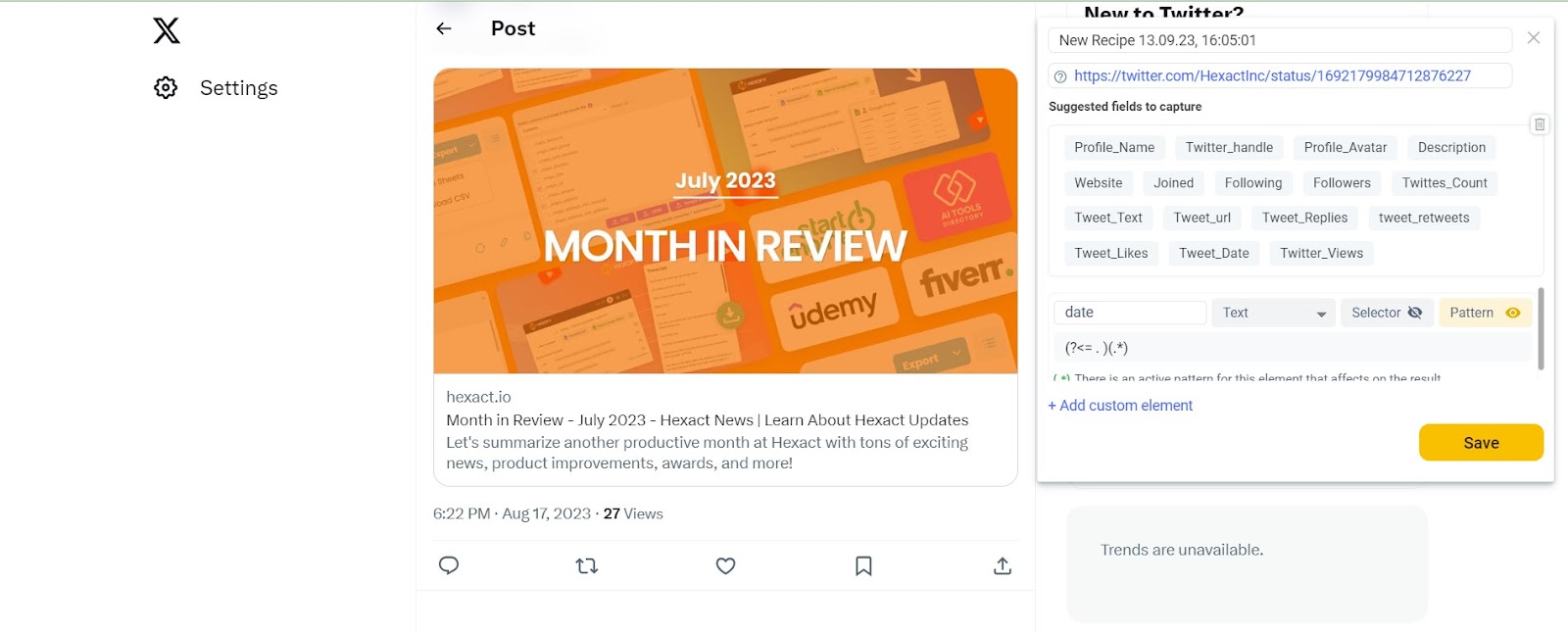
Navigate to the Twitter page you want to scrape, such as https://twitter.com/HexactInc/status/1692179984712876227.
Click on the “New Template” button and locate the element that contains the post date and time information, typically displayed under the tweet.
Step 2: Enter the following pattern: (?<= . )(.*)
Once you click on the date, you will be able to copy and paste the pattern inside the Pattern field.
The regex pattern, (?<= . )(.*?), serves the purpose of extracting the date from the specified element. Let’s break down this pattern for a clearer understanding:
The part (?<= . ) is a positive lookbehind assertion that verifies the presence of a space and a period before the matched text. It ensures that the text capture starts immediately after the space and period.
The (.*?) portion captures any sequence of characters using a non-greedy approach. This means it captures the smallest possible sequence of characters that still meets the pattern’s criteria.
Step 3: Save the element
Once you’ve applied the regex pattern to the designated element, click on the “pattern” again and you’ll be able to retrieve the text that matches it.
After creating the first pattern for the date, you should add the one related to the time.
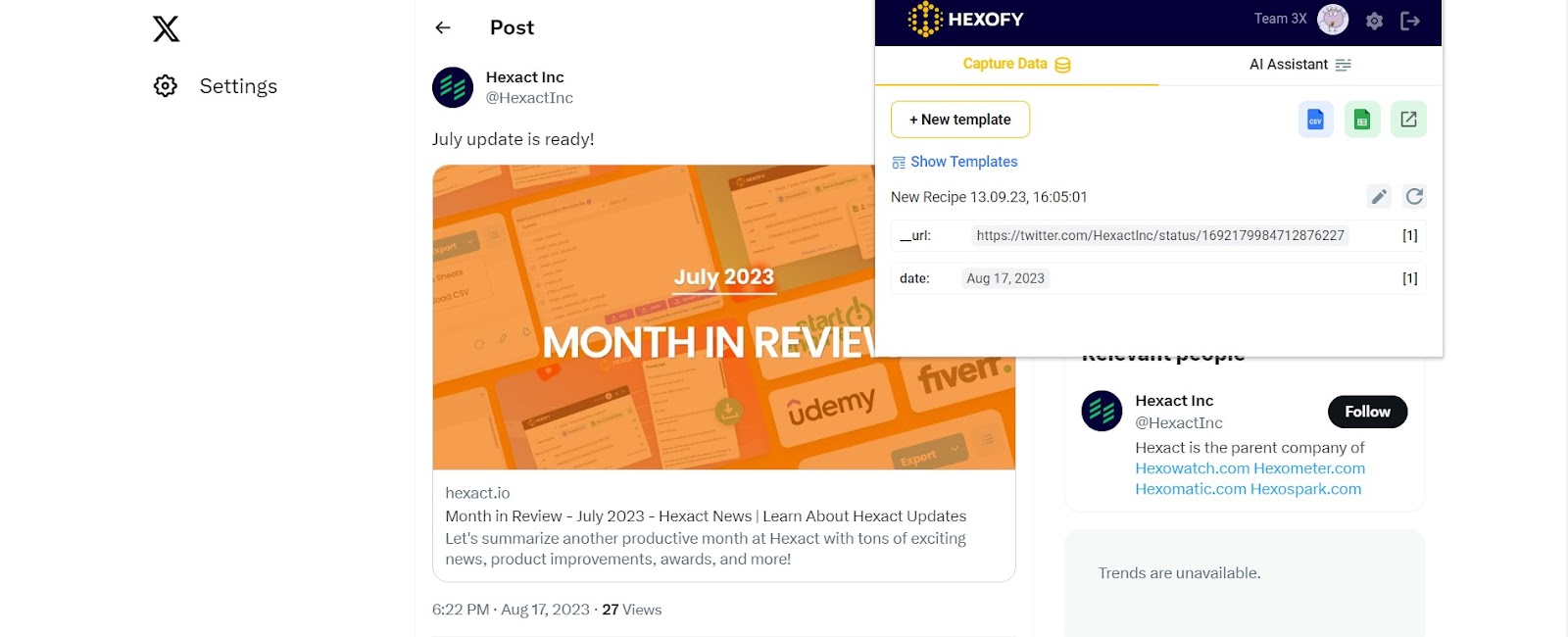
Scrape post time:
Step 1: Select the relevant element
Similarly, choose the Tweet you need to scrape and locate the element that contains the post time information.
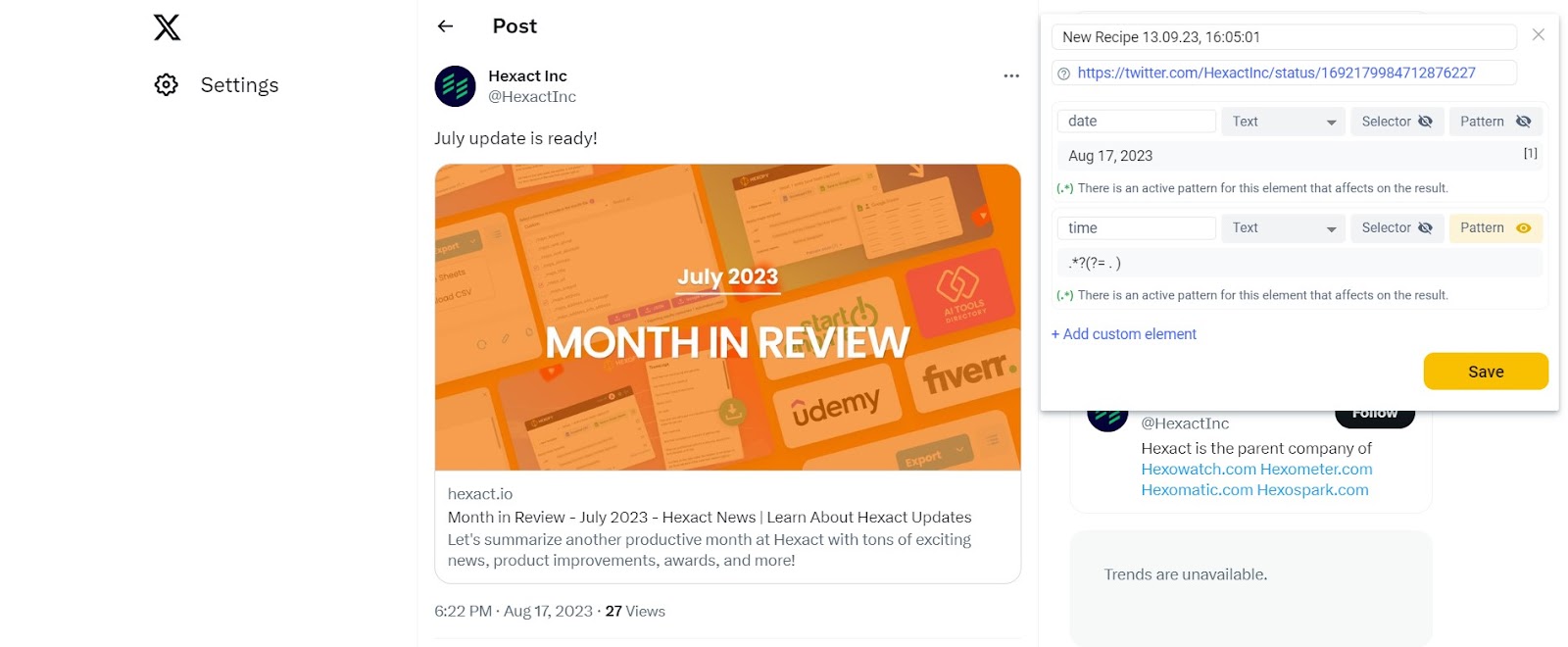
Step 2: Enter the following pattern: .*?(?= . )
After clicking on the time, you will be able to copy and paste the pattern .*?(?= . ) into the Pattern field.
This regex pattern, .*?(?= . ), is used to extract the time from the selected element.
Here’s why this pattern is used to extract the time:
.*? matches any characters (the .*? part) in a non-greedy manner, capturing as few characters as possible.
(?= . ) is a positive lookahead assertion that checks for a space and a period immediately after the matched text. It ensures that we stop capturing text before the space and period.
Step 3: Save the element
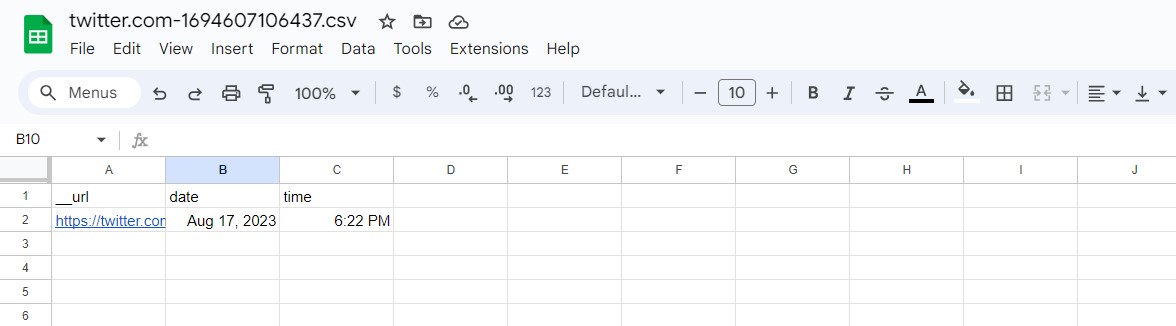
After applying the regex pattern to the selected element, you extract the matched text, which should represent the time.
The extracted time can then be saved in a Google Spreadsheet for further analysis or processing.
Indeed: Get the city, state, and zip code in separate columns
Now it’s time to scrape the city, state, and zip codes of job offers on Indeed:
Scrape the city:
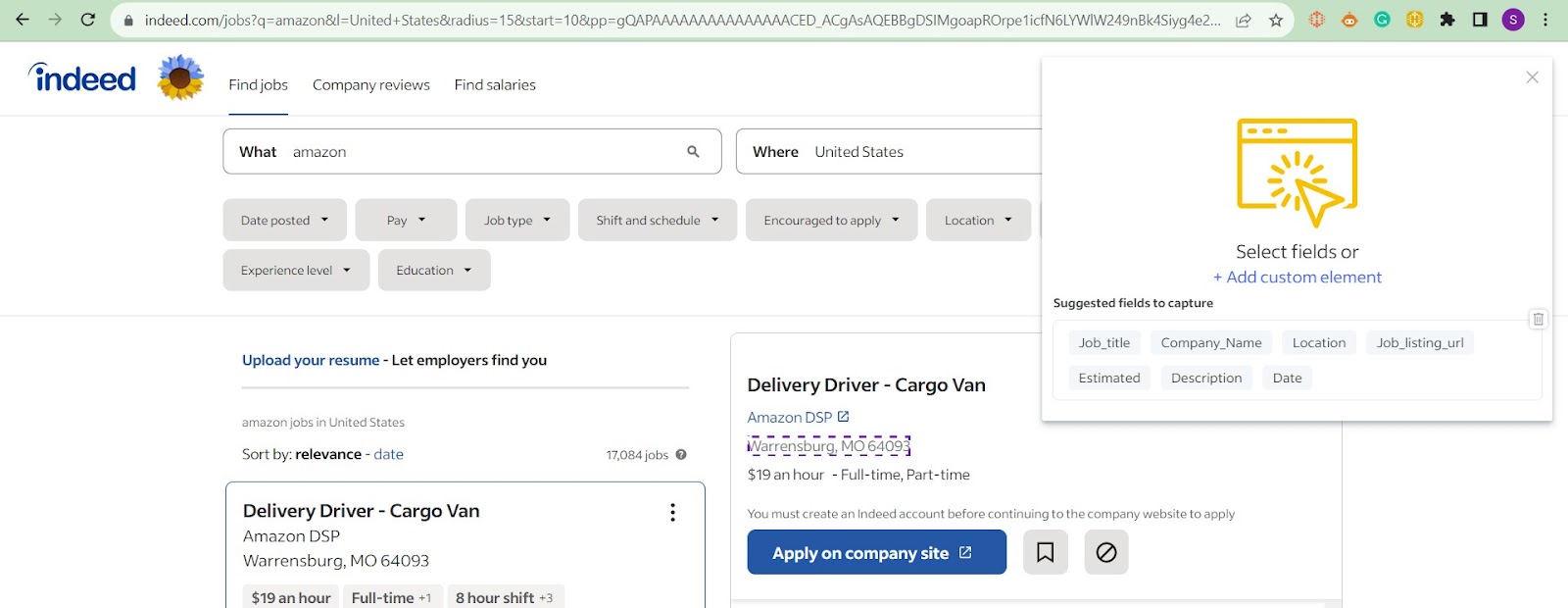
Step 1 – Identify the city element:
Begin by clicking on the “New template” button and locating the element on the webpage that contains the city information.
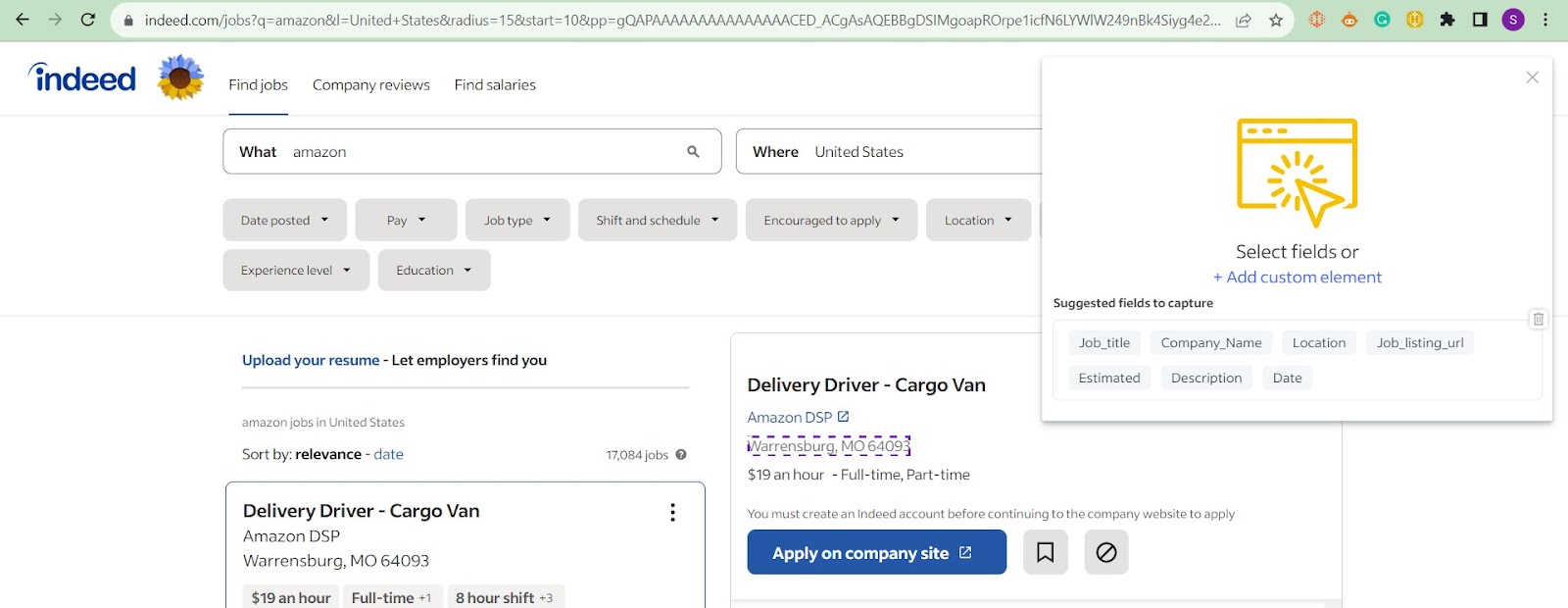
You can use the following CSS selector for this purpose:
#mosaic-provider-jobcards > ul > li > div > div.slider_container.css-8xisqv.eu4oa1w0 > div > div.slider_item.css-kyg8or.eu4oa1w0 > div > table.jobCard_mainContent.big6_visualChanges > tbody > tr > td > div.heading6.company_location.tapItem-gutter.companyInfo > div > div
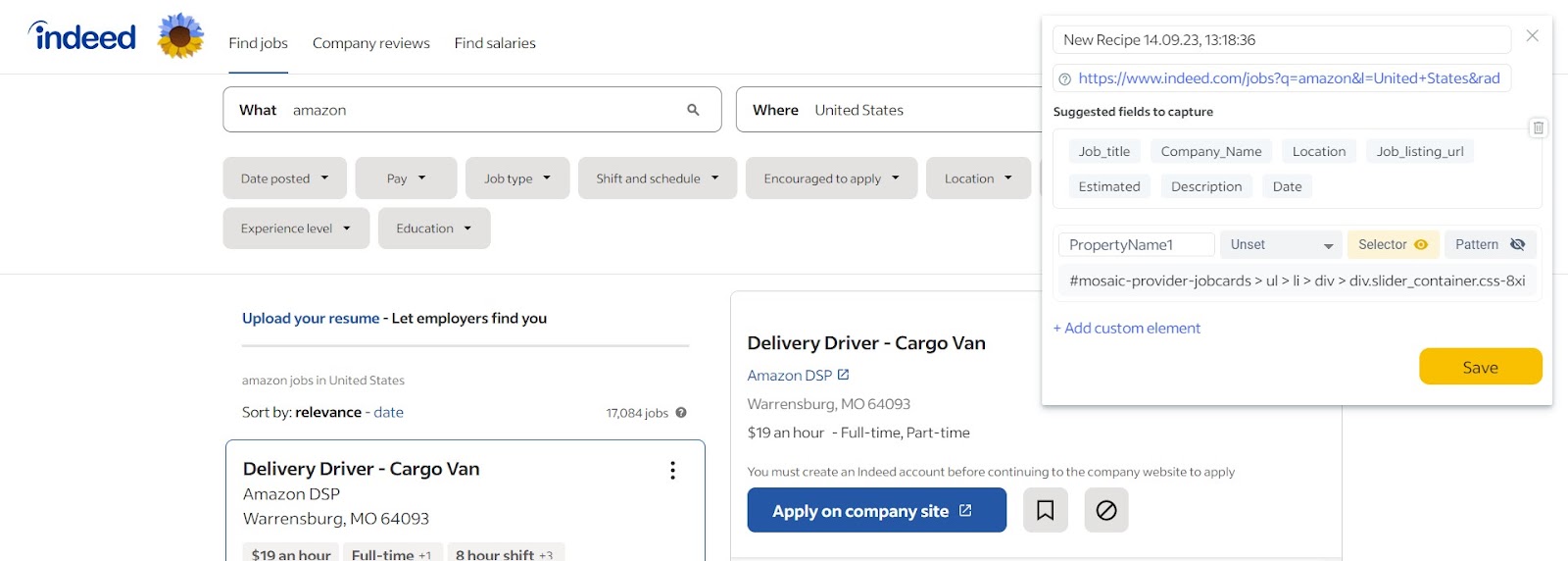
Step 2 – Define the Regex pattern: .*?(?=, )
Enter the following regex pattern: .*?(?=, ). This pattern captures any characters that appear before a comma and space (, ) in the selected element.
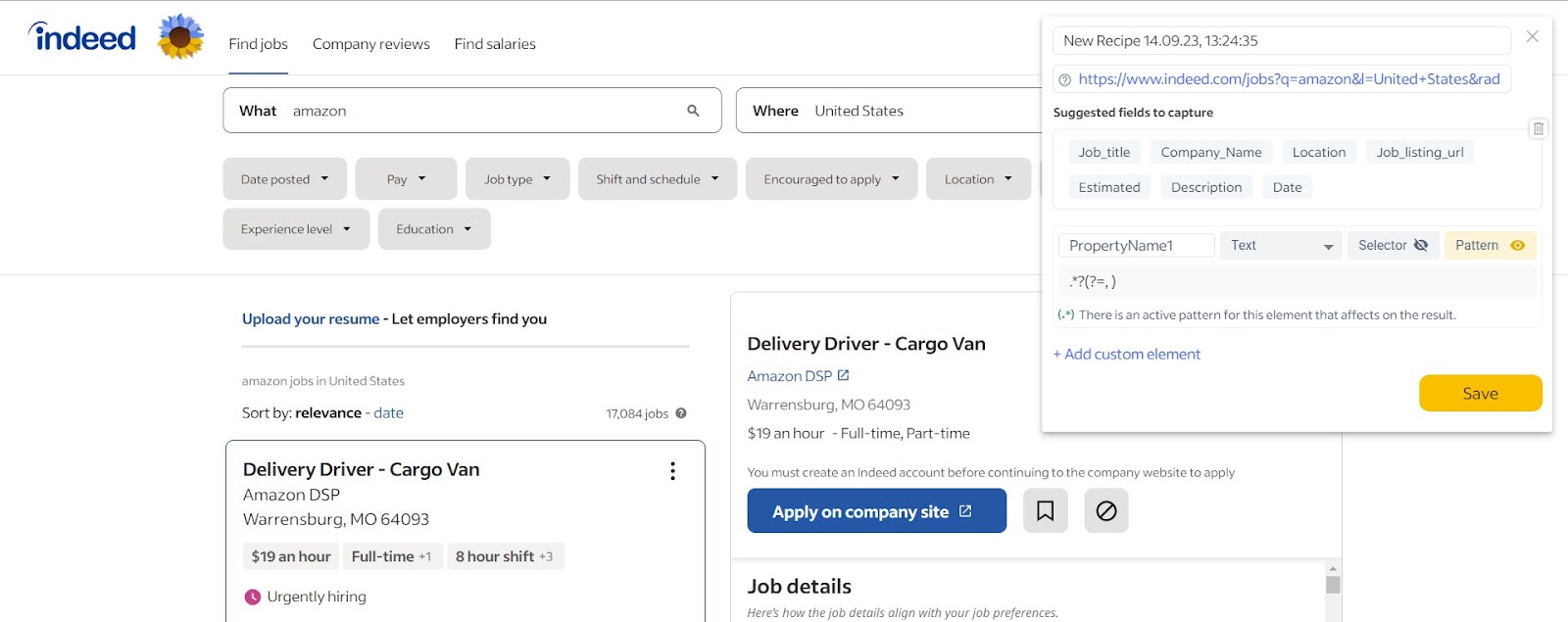
Step 3 – Save the element:
After applying the regex pattern, you will have extracted the matched text, which should correspond to the city. Save this extracted city data for further use or analysis.
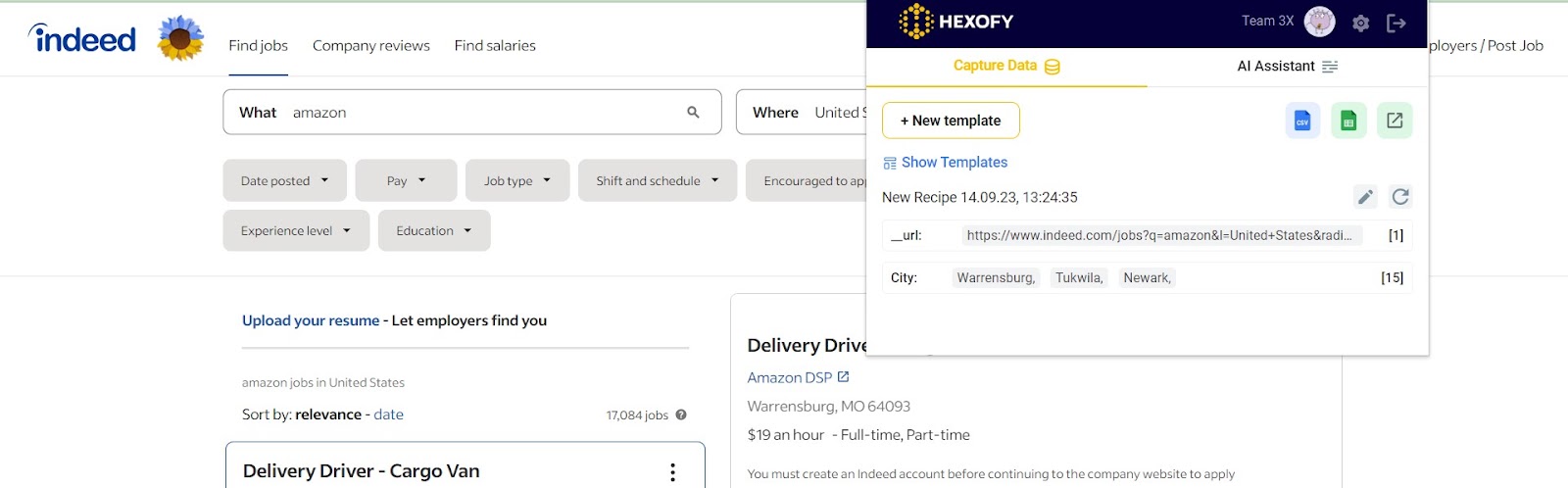
Scrape the state:
Step 1 – Locate the state element:
Just like with the city, find the element that contains the state information on the same webpage. You can use the same CSS selector as in the previous step:
#mosaic-provider-jobcards > ul > li > div > div.slider_container.css-8xisqv.eu4oa1w0 > div > div.slider_item.css-kyg8or.eu4oa1w0 > div > table.jobCard_mainContent.big6_visualChanges > tbody > tr > td > div.heading6.company_location.tapItem-gutter.companyInfo > div > div
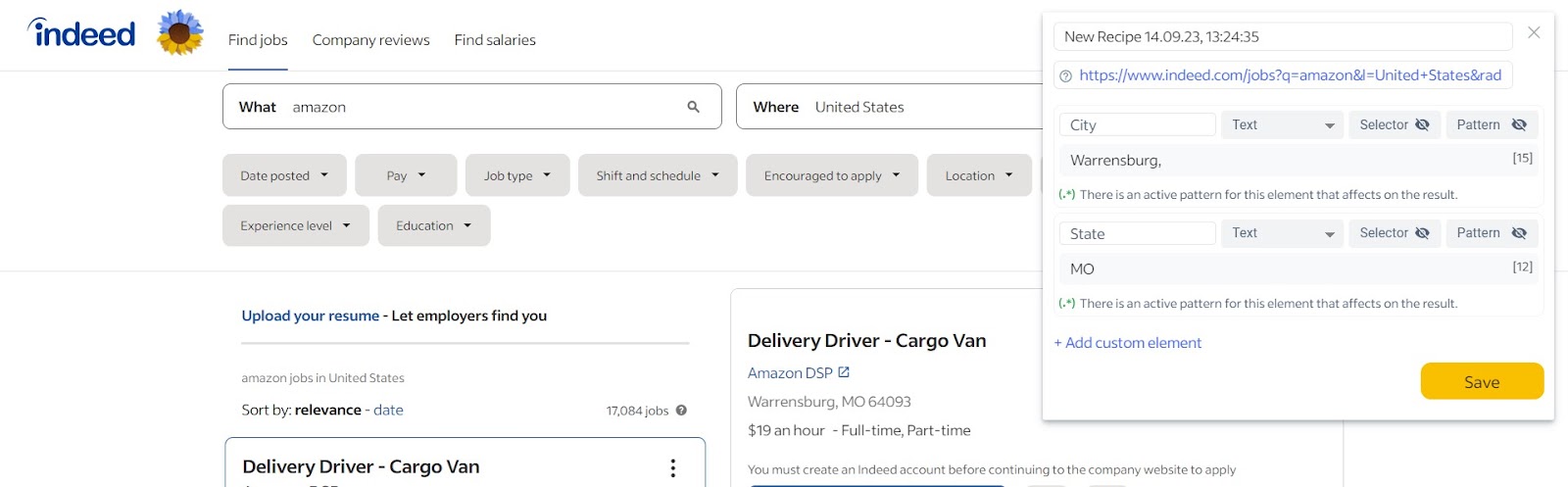
Step 2 – Specify the Regex pattern: (?<=, ).*?(?= )
Enter the following regex pattern: (?<=, ).*?(?= ). This pattern captures any characters that appear after a comma and space (, ) and before a space ( ) in the selected element. This effectively extracts the state information.
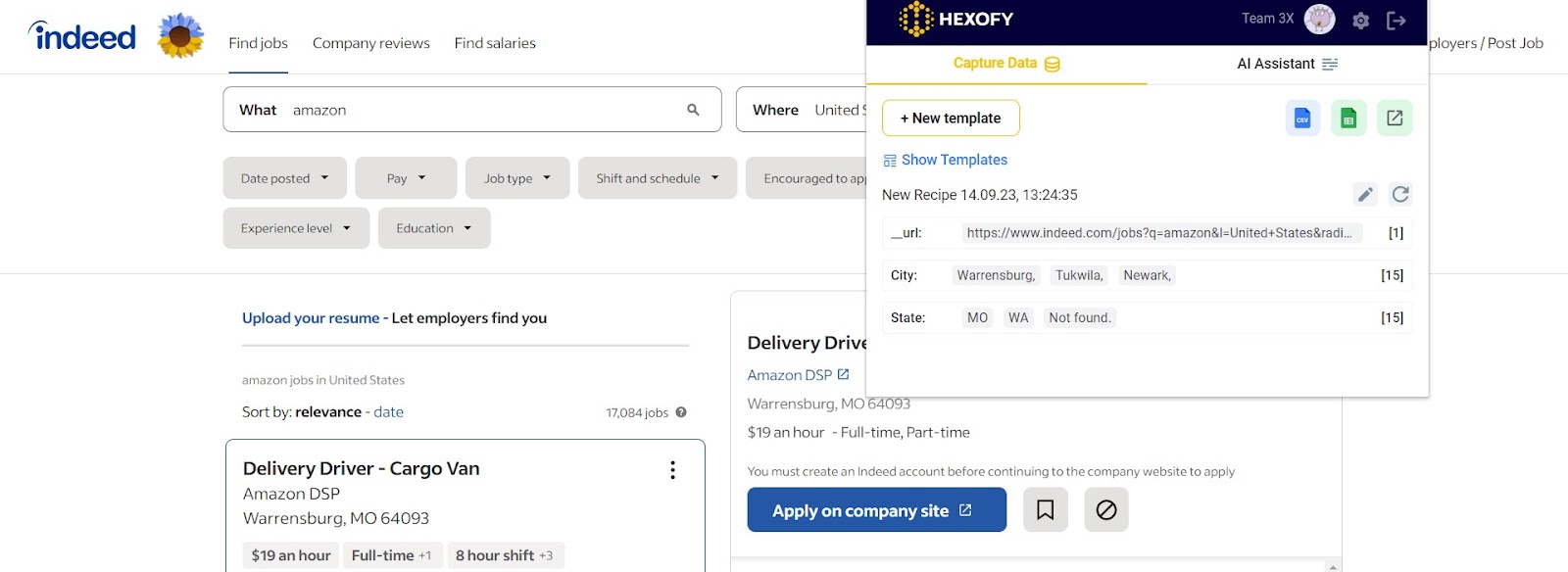
Step 3 – Save the element:
After applying the regex pattern, you’ll have extracted the matched text representing the state. Save or utilize this extracted state data as needed.
Scrape the zip code:
Step 1 – Find the zip code element:
Locate the element that contains the zip code information on the same webpage. Once again, use the same CSS selector:
#mosaic-provider-jobcards > ul > li > div > div.slider_container.css-8xisqv.eu4oa1w0 > div > div.slider_item.css-kyg8or.eu4oa1w0 > div > table.jobCard_mainContent.big6_visualChanges > tbody > tr > td > div.heading6.company_location.tapItem-gutter.companyInfo > div > div
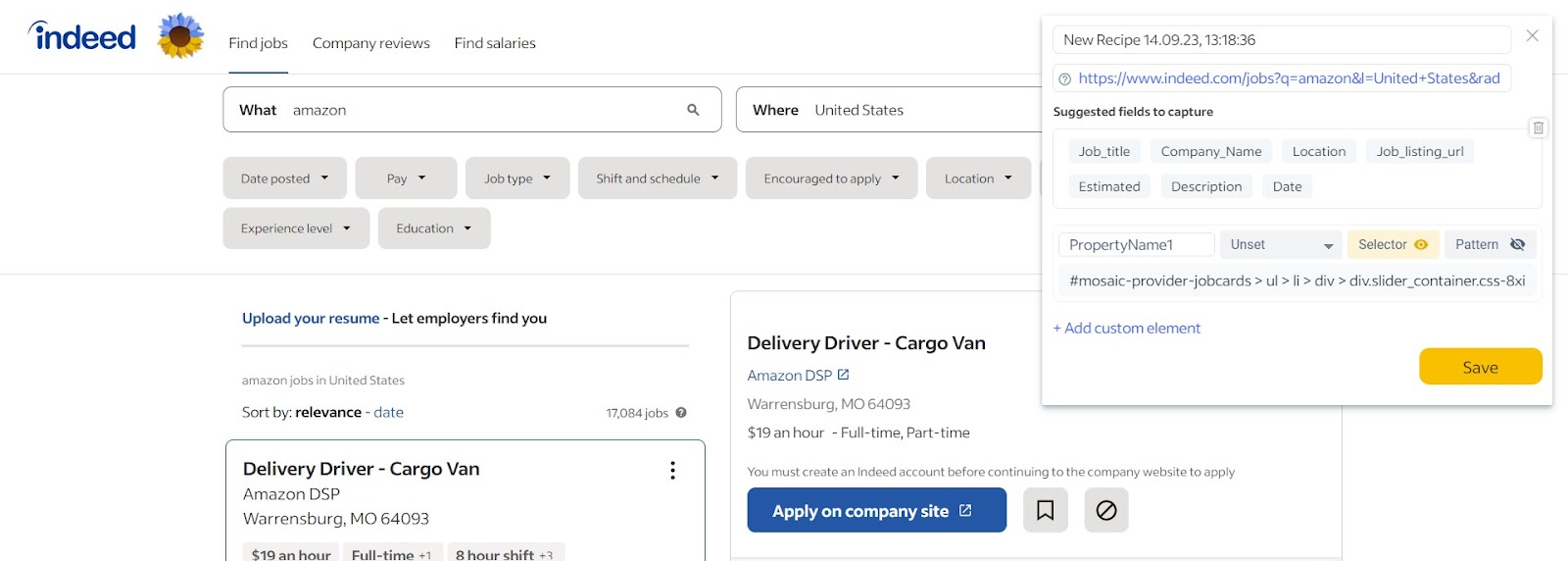
Step 2 – Specify the Regex pattern: [0-9]+
Enter the following regex pattern: [0-9]+. This pattern matches and captures one or more digits, which represent the zip code, in the selected element.
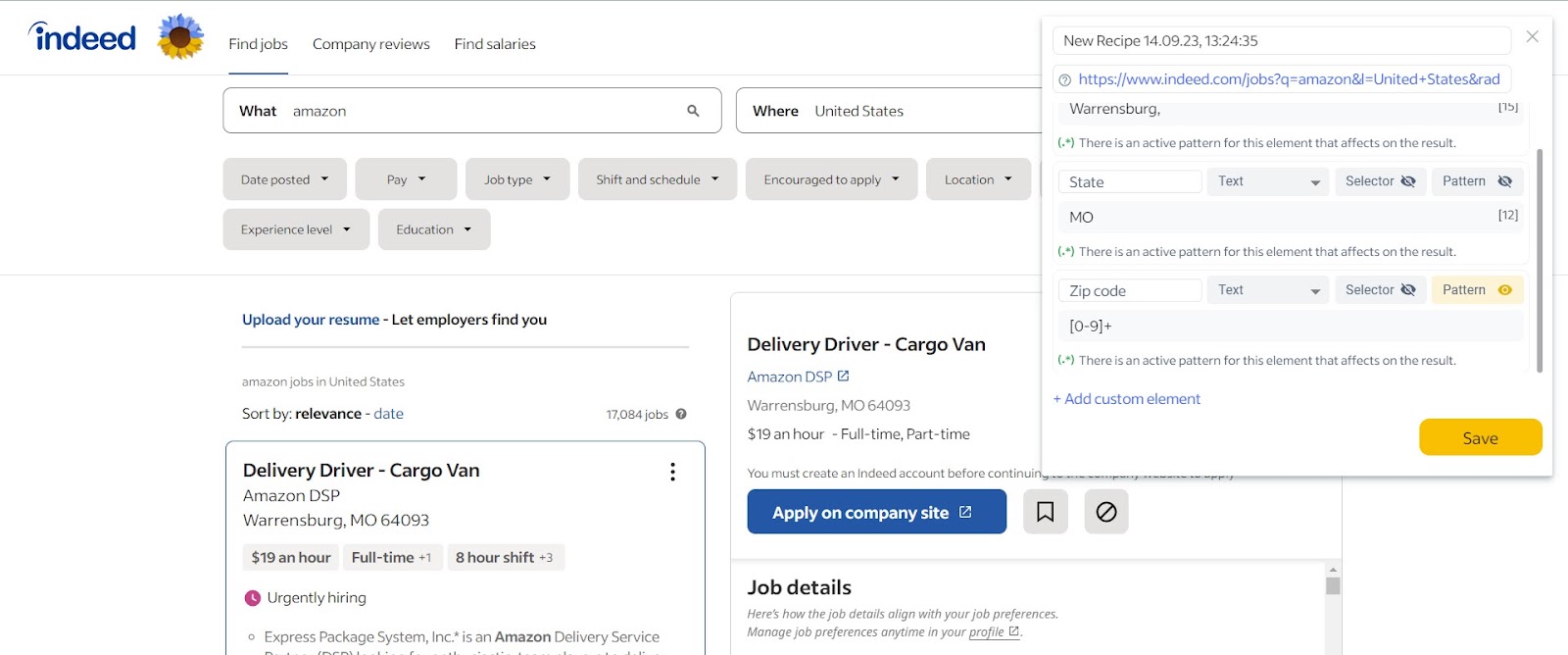
Step 3 – Save the element:
After applying the regex pattern, extract the matched digits representing the zip code. Save or use this extracted zip code data according to your requirements.
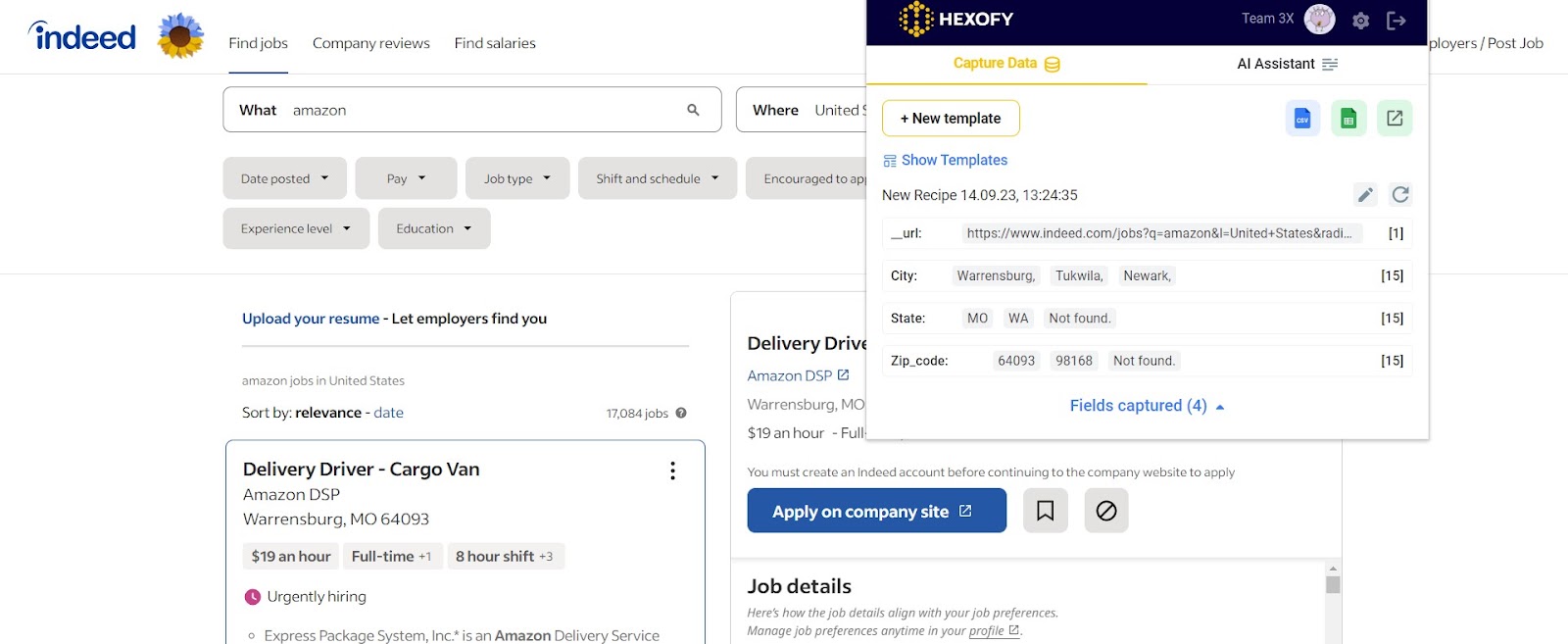
Now you know how to use Regex patterns when scraping with Hexofy! By following these steps and utilizing the provided CSS selectors and regex patterns, you can accurately scrape and separate the required information from the specified webpage.
Capture data from any page, like magic.
Get started free by installing our super simple to use browser extensions.



Content Writer | Marketing Specialist
Experienced in writing SaaS and marketing content, helps customers to easily perform web scrapings, automate time-consuming tasks and be informed about latest tech trends with step-by-step tutorials and insider articles.
Follow me on Linkedin